What Is a GitOps Workflow and How Does It Work?

GitOps is a model that enables a streamline between development and operations flows. It brings them together through a central place for collaboration, Git, containing both configuration files and application code.
GitOps serves organizations that develop cloud-native solutions based on containerization and microservices. It enhances the developers' experience by enabling them to contribute with features without the need to know the underlying infrastructure. At the same time gives control to operations with code reviews and approvals.
GitOps improves the stability and reliability of the system and provides higher security guarantees. But the most prominent advantages coming with implementing a GitOps model in your company are probably standardization and consistency in your overall workflow.
In this article, we cover what you need to consider to develop a successful GitOps model:
What Is GitOps?
GitOps is an operational framework that uses Git repositories, or principles, as a single source of truth. It uses DevOps practices for software development, such as CI/CD, compliance, version control, collaboration, and more. Then these practices are applied to automate the IT infrastructure.
GitOps helps teams and developers perform application and infrastructure management activities using development tools, processes, and techniques. Git is an open-source version control system (VCS).
A simple GitOps definition is the use of Git repositories to manage and automate infrastructure and application deployments, ensuring consistency, transparency, and control through versioned code changes.
Key Principles Behind GitOps
Understanding the main principles of GitOps is essential for its correct implementation. Let's explore them in more detail.
Version Control of Infrastructure
Version control enables teams to manage code effectively. Software development teams may work together on code development more quickly and effectively when version control is available. This speeds up time and reduces interruptions and outages.
Automated Deployments and Rollbacks
Another crucial part of GitOps is the automation of deployments and rollbacks. Every change in the infrastructure or app configurations is automatically deployed to the Git repository. Since every change is version-controlled, rollbacks are a great seamless solution for faster recovery and reduced downtime.
Git-based Approvals and Audits
All changes go through standard Git workflows such as pull requests (PRs) or merge requests (MRs), enabling teams to review and approve updates before they are applied. Also, Git provides a complete audit because every change is monitored, the time, and by whom. These audits are essential for security, compliance, and debugging.
Declarative Infrastructure as Code
A declarative approach is used when you want to specify which services you want to run as an end state of the system, rather than describe how it can be done. These declarations are stored in Git as Infrastructure as Code (IaC) and ensure that the live system matches the defined state. Tools like Terraform, Helm, Kubernetes, and AWS CloudFormation use this approach.
What Is a GitOps Workflow?
The GitOps concept involves developers committing infrastructure configurations and code changes to Git repositories. The cycle typically follows several steps:
- A change is proposed (code or configuration).
- That change is committed and pushed to a Git repository.
- A deployment tool detects the change and applies it to the infrastructure.
- The system is monitored, and rollbacks are handled via Git if needed.
This workflow makes infrastructure management more consistent and reliable.
How a GitOps Workflow Works – Step-by-Step
A GitOps workflow automates the deployment process by connecting Git repositories with infrastructure environments. Below is a step-by-step GitOps explained:
Step 1: Developer Makes a Code or Config Change
The workflow starts when a developer makes a change to the application code or infrastructure configuration, such as updating a Kubernetes deployment file, modifying a Helm chart, or altering a Terraform module.
Step 2: Commit and Push to Git Repository
Once the change is complete, the developer commits and pushes it to a Git repository. This serves as a version-controlled record of the intended state of the system, allowing teams to track, review, and approve changes.
Step 3: Git Triggers a Deployment Tool (like Argo CD or Flux)
Argo CD and Flux are two examples of GitOps solutions that continuously monitor the Git repository. They immediately start the deployment process when they find a new commit or merge to a tracked branch.
Step 4: Tool Syncs the Change to the Cluster
The cluster's present state and the planned state from Git are compared by the deployment tool. If there is a gap, it provides the required adjustments to align the system with the Git-defined configuration.
Step 5: Monitor and Roll Back if Needed
The system is continuously monitored to ensure it matches the desired state. Operators are able to quickly return to an earlier version by going back to the Git commit in case something goes wrong. After that, the deployment tool automatically reapplies that version.
To successfully implement GitOps, teams should explore various GitOps resources such as tutorials, tools, and best practices to streamline their workflow.
Benefits of Using a GitOps Workflow
With GitOps benefits, you can streamline workflows, reduce manual errors, and promote transparency through transparent change management and audits. Some of the key benefits that GitOps offers are:
Easier Auditing and Traceability
With every change tracked in Git, teams can see exactly who made what change, when, and why. This transparent audit simplifies compliance and makes debugging easier.
Faster Recovery from Failure
Rollback is a simple step in GitOps. GitOps tools detect the rollback and immediately restore the system to its last known good state, reducing downtime and stress.
Fewer Manual Steps
The entire deployment process is automated. Developers don’t need to manually apply changes with CLI tools or scripts, which minimizes human error and speeds up delivery.
Stronger Security with Git as the Gatekeeper
All changes must go through Git, which means organizations can enforce policies such as code reviews, approvals, and access control at the Git level, adding an additional layer of security.
Common Challenges with GitOps
While there are lots of benefits that GitOps provides, teams may face certain challenges throughout the process that need more focus. Some of them are:
Managing Secrets Securely
This is a major challenge within the GitOps workflow. Sensitive data like API keys and passwords shouldn't be stored in plain text in Git. Managing secrets in a secure, encrypted, and automated way can be complex and requires extra care.
Keeping Git and Actual State in Sync
In GitOps, the challenge of keeping Git (desired state) and the actual state in sync is a core principle. Teams must enforce GitOps discipline to ensure Git remains the true source of truth.
Tooling Complexity for New Users
GitOps promises simplicity, but in practice, it often introduces a complex toolchain. The supporting tools come with a steep learning curve, which requires prior experience.
Everything as Code
Start by declaring your infrastructure as code. CloudFormation, Terraform, Palumi, Crossplane are some possible declarative languages you can use to define the configuration of how you want your infrastructure to look.
Declarative code improves readability and maintenance. In addition, the practices that are part of your application code lifecycle can now be replicated to your infrastructure code as well.
In GitOps, it's common practice to use a Git repository for your IaC development. That way, you can explore the benefits such as version control, collaboration, and audits.
With technologies like Docker and Kubernetes, developing environment setup became much more manageable. You define system dependencies as code. In a dockerfile, you define your environment, versions, configurations, and dependencies, and Docker enforces those definitions on runtime.
GitOps is not limited to only infrastructure as code. Anything that can be defined as code can also use the GitOps model. This includes security, policy, compliance, all operations beyond infrastructure.
Review process
When working with application code, it's common practice to have multiple features that need to be implemented simultaneously. Therefore, leveraging a version control system is a must for software development these days, as various teams collaborate on the same codebase, and mechanisms to merge all those changes need to be in place.
If you already take advantage of the Git flow system by working with feature branches and pull requests, then you won't need to invest much in a new process for your GitOps workflow. Furthermore, as your infrastructure (and other operations) are defined as code, you'll be able to implement the same practices for code review.
A proper Git flow consists of forking or creating a new feature branch from the main branch. When someone does changes to the code, they make a pull request that should be reviewed by other team members who haven't worked on that code. They review the code, validate it and then approve it. Once approved, the code can be merged into the main branch and delivered to test or production.
This way, you can track who made which change and ensure the environment has the correct version of the code.
The same can be done with infrastructure. In an infrastructure model, typically, the main branch represents an environment, like dev, test, stage, prod, and the state running on that environment. With pull requests, developers can collaborate with operations for peer review, and security and compliance experts can also be involved in this stage to validate the environment's state properly.
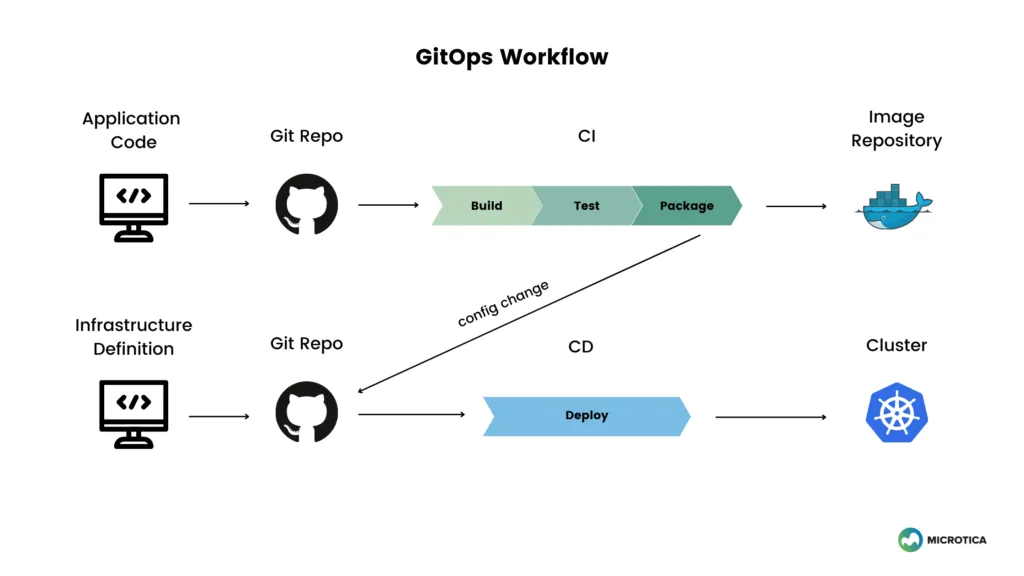
Separate build and deploy process (CI and CD)
In DevOps practices, the CI/CD process is considered one entity and typically delivered in one pipeline. But with the rise of componentized applications, the pipeline between development and operations becomes more complex.
A CI (continuous integration) process is responsible for building and packaging application code into containers images.
The CD (continuous deployment) process is a crucial part of implementing GitOps. This process executes the automation to bring the end state in line with the system's desired state, described in the repository code. This is done upon a successful merge of the code in the main branch.
Ultimately, GitOps sees CI and CD as two separate processes. CI as a development process and CD as an operational process. The GitOps workflow model brings the two together.
A GitOps approach commonly used to separate these processes is to introduce another Git repository as a mediator. This repo contains information about the environment, and with every commit there, the deployment process is triggered. This way, the CI process never touches the underlying infrastructure, like the Kubernetes cluster.
Decoupling the build pipeline from the deployment pipeline is a powerful protection against misconfigurations and helps achieve higher security and compliance.
Conclusion
GitOps as an operational model uses DevOps practices known to many teams, such as IaC, version control, code review, and CI/CD pipelines.
Using GitOps, you can automate the infrastructure provisioning process and use Git as a single source of truth for your infrastructure. This is why to create a successful GitOps model, you need a declarative definition of the environment.
It would be best if you also had a pull request workflow in your team. To be able to collaborate on the infrastructure code and create operational changes, you should open a pull request. Senior DevOps engineers and security experts then review the pull request to validate the changes and merge into the main branch if everything is okay.
And at last, for a full GitOps implementation, you need to have CI/CD automation for provisioning and configuration of the underlying environment and the deployment of the defined code.
GitOps helps improve the collaboration between developers and operation teams, their productivity, and increases deployment frequency. With these improvements, teams can release faster and more secure to maintain their position in the market.
FAQ
What Are the Steps in Gitops?
GitOps success relies on three key steps:
1. Everything as Code – define infrastructure, configuration, and policies as code for transparency and control.
2. Review Process – use PRs for peer-reviewed, auditable changes
3. Separate CI/CD – split build and deploy for secure, automated delivery.
What Is the GitOps Framework?
Continuous integration/continuous delivery (CI/CD) and version control are two DevOps approaches that form the core of the GitOps operational framework.
What Is the GitOps Strategy?
GitOps is a software delivery strategy that works by using a Git-based source code management system as the single source of truth.

Relevant Posts


.webp)