Amazon Bedrock & Retrieval Augmented Generation (RAG): Building Smarter AI Systems with Context-Aware Response
In Part 1 of this series, we delved into Amazon Bedrock and how DevOps engineers and developers could build their first generative AI applications and deploy with AWS Lambda. In the last blog post, we also focused on use cases that could be built with Amazon Bedrock even best practices for working with Amazon Bedrock.
In this follow-up, we’ll go a step further and focus on a key challenge in generative AI: delivering context-aware responses that are accurate and relevant. In this tutorial, you'll learn how to use Amazon Bedrock with Retrieval-Augmented Generation (RAG), understand the underlying structure, and follow a hands-on guide to integrating the two effectively.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) is a technique used to improve the quality of responses from LLMs by adding relevant information from external sources. Normally, when working with a traditional LLM, you get responses based on what they’re trained to give back, but with RAG, you get responses from real-time data and more accurate information. Working with standard models can be static, whereas working with RAGs is super dynamic; that’s a major difference.
RAG vs. Standard LLMs
In this section of the tutorial, we will look at some of the differences in features between Standard LLMs and RAG-Enabled LLMs.
In the table above, you'll see that working with traditional LLMs can be very static, fixed, and inaccurate because they operate based on how humans fine-tune the model. However, RAG-Enabled LLMs work directly with data retrieved from external sources and real-time data.
Use-Cases of RAGs
- Chatbots: This is probably the most known use-case for RAGs. With RAGs, you get more accurate and current information as responses for better customer interactions.
- Internal Knowledge Search: RAG-enabled models enable users to easily access and utilize articles, guides, documentation, and even other public resources without any manual intervention or worrying if the information generated is relevant.
- Support Automation: RAGs could also improve incident resolution by pulling from logs and past tickets. It helps provide quicker and accurate answers for resolving issues faster.
- Financial Services: RAG-enabled models can also generate stats reports in different formats based on real-time market data.
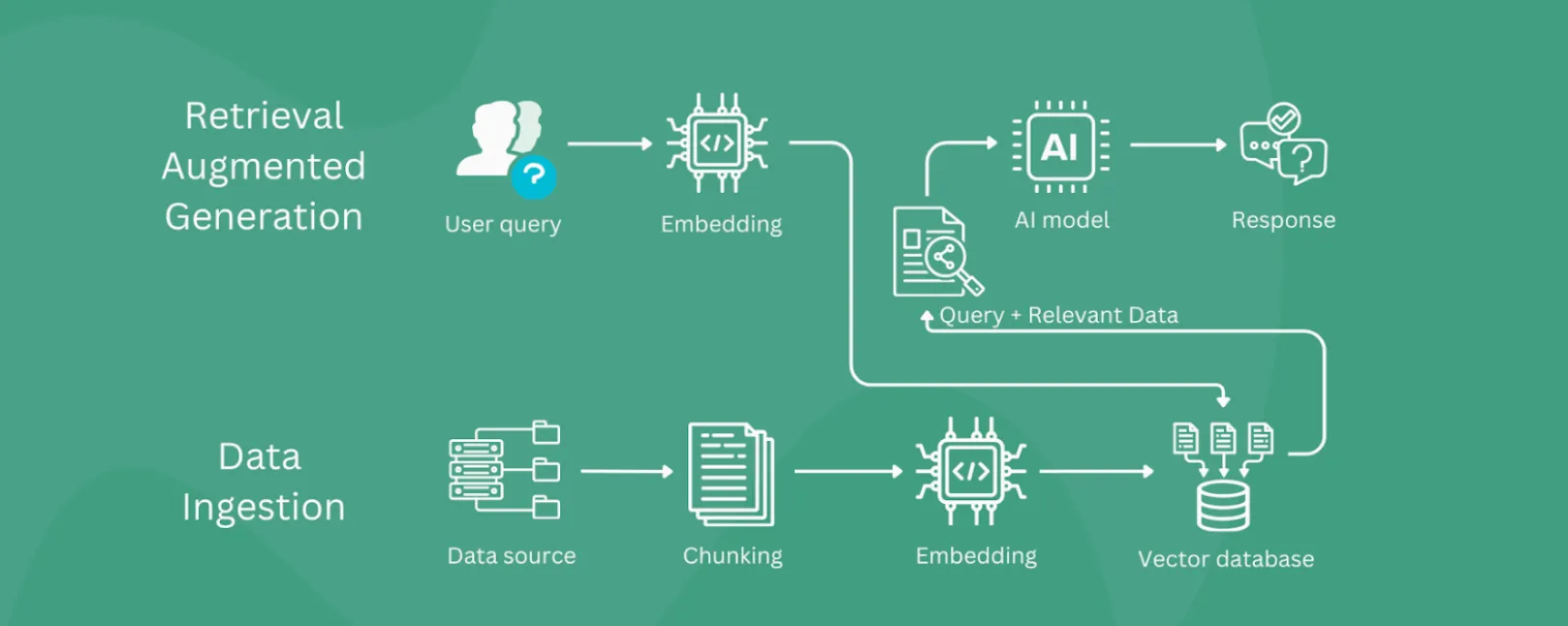
How Does Retrieval Augmented Generation Work?
RAG improves AI responses by using information retrieval with language models. For example; when a user submits a query, the system uses an existing knowledge base like S3, Elasticsearch, Pinecone, or OpenSearch to find relevant data. This data is added to the user’s query and sent to the AI model to make the response more accurate.
Here’s an architectural diagram of how RAG works:

Benefits of Using RAG-Enabled LLMs
- Lower Risk of Inaccurate Information: Using RAG-Enabled LLMs generates responses based on reliable sources rather than making assumptions. Unlike using standard LLMs, where you have to provide models with data that might be inaccurate.
- Improved Accuracy: Using them also ensures AI responses are more accurate and up-to-date by retrieving information from trusted external sources instead of relying on fine-tuned data. This reduces the risk of giving users incorrect information for responses, thereby improving the accuracy of generated content.
- Cost Efficiency: They also help save money and reduce API calls by using existing data sources instead of making unnecessary requests.
- Security & Compliance: Using RAG-Enabled LLMs even helps provide data privacy by retrieving information only from authorized and secure sources.
AWS Bedrock + RAG: The Perfect Match
AWS Bedrock provides a solid base for RAG-enabled apps by offering various foundation models with built-in tools for storing and retrieving custom data.
Its serverless setup ensures that there is security and compliance while integrating with services like Amazon OpenSearch for search-based retrieval, Amazon S3 for storage, AWS RDS for relational databases, and Amazon Bedrock Knowledge Bases for vector-based retrieval. This setup allows developers to create scalable AI applications easily.
Before delving into implementing RAG into Amazon Bedrock, lets have a look at Amazon Bedrock’s workflow:
How to Implement RAG with AWS Bedrock
Step 1: Store Your Custom Data
Since we will be using Amazon S3 to store our data, follow these steps:
- Head over to Amazon S3.

- Create an Amazon S3 Bucket to store your data and make necessary configurations. Be sure to enable Bucket Versioning.

- Upload to documents to your Amazon S3 bucket.
Step 2: Choose an Embedding Model
Choose any model to work with; your decision on selecting a model should be based on whether it fits the project you're working on. Refer to this guide to find a list of models you can work with.
Step 3: Create a Knowledge Base
- Navigate to Amazon Bedrock’s Console
- In the side navigation by the left, select "Knowledge bases".
- Click "Create knowledge base" and select the “Knowledge Base with Vector Store” option.
- Provide the knowledge base details
- When providing the knowledge base details, choose the S3 URI location as data source.
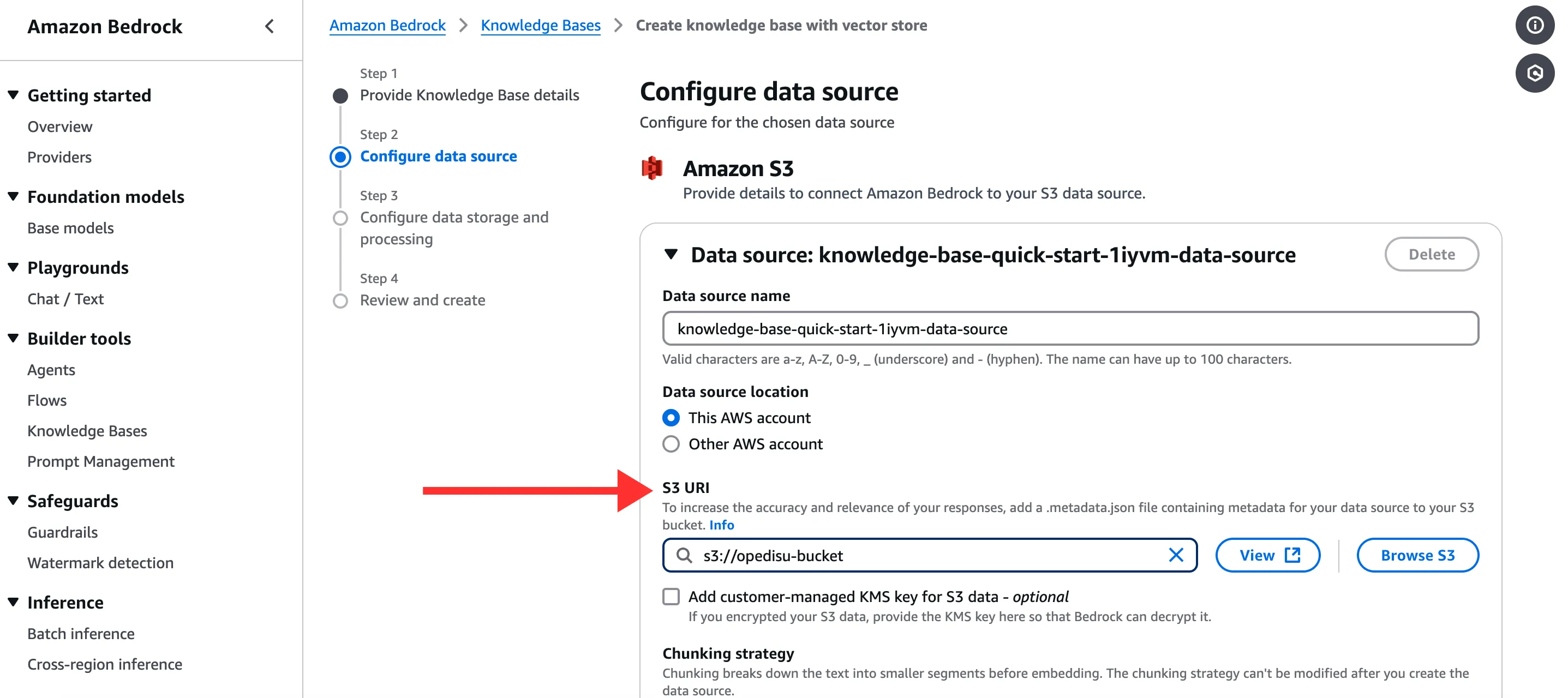
- Finally, select your embedding model.

- Configure the vector store (Amazon OpenSearch Serverless will be used by default).
Step 4: Chunking (Data Preparation):
- Head over to the Knowledge Base in the Amazon Bedrock console.
- Select Your Knowledge Base From the Knowledge Bases section, choose the knowledge base you want to work with.
- Add or Edit a Data Source If you haven't already, add a new data source pointing to your S3 bucket. If you have an existing S3 data source, select it for editing.
- Configure Chunking Strategy In the data source settings, look for the "Chunking Configuration" section. Here, you'll find options to set your chunking strategy:
- Fixed-size chunking.
- Hierarchical chunking.
- Semantic chunking.
- No chunking (treats each file as one chunk).
Here’s where to configure that:
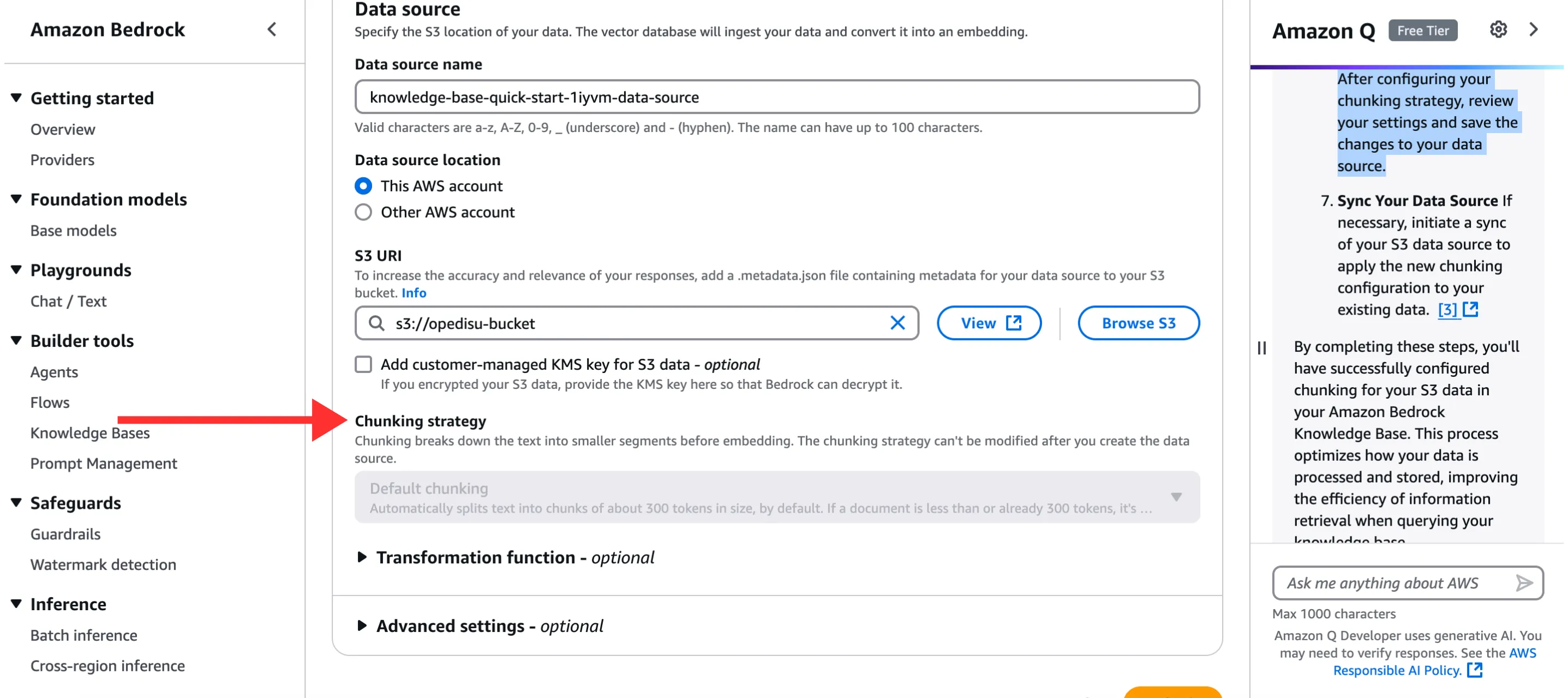
- Choose and Configure Your Chunking Strategy Select the strategy that fits your data and use case.
- For Fixed-size: Specify the number of tokens per chunk and overlap percentage.
- For Hierarchical: Also define parent and child chunk sizes and overlap.
- For Semantic: Set the maximum tokens, buffer size, and breakpoint percentile threshold.
- Review and Save Changes After configuring your chunking strategy, review your settings and save the changes to your data source.
Step 5: Test and Query the Knowledge Base
- Before testing, ensure the data is synced; syncing means fetching the data from S3, chunking it, embedding it, and storing it in the vector database.
- In the knowledge base console, hit the Test button.

- When the panel pops out, enter a question related to your uploaded documents.
- Click Run to get AI-generated responses.
Step 6: Verify the Retrieval Process
- If Bedrock correctly retrieves relevant data, your RAG setup is working.
Best Practices & Tips for RAG Pipelines on AWS Bedrock
- Optimize Context Window: It's important to keep the context clear and focused on what's needed for the prompt. Too much information can confuse the model, so a great thing to do will be always try to provide only necessary data to get accurate responses.
- Balance Cost vs. Accuracy: Retrieving more data also helps improve accuracy, but it can also increase costs. Find a balance by fetching only the necessary data to reduce costs while maintaining the same quality.
- Fine-Tune Retrieval Thresholds: Set limits for retrieval relevance to make sure you're only getting the most useful data. This helps prevent overwhelming the model with unnecessary information and keeps responses clear.
- Use Caching: Cache frequently used data to speed things up and reduce unnecessary API calls. This makes your pipeline more efficient and reduces costs, especially for common queries.
- Secure Data Sources: Protect your data by using IAM policies and encryption for sensitive sources. This practice ensures that only authorized users can access your data, keeping everything safe and compliant.
Best Use Cases for RAG
- DevOps & Observability: You can use RAG for retrieving logs and metrics (in real-time) for automated incident resolution.
- Product Search & Recommendations: You can use RAG to refine personalized product recommendations.
- Enterprise Document QA: You can also use RAG for employees to query company documents with chatbots and AI agents.
- E-Commerce: You can also use RAGs to fetch dynamic product descriptions and search results.
RAG vs. Fine-Tuning Decision Framework
What’s Next: RAG-Enabled AI Agents in Production
Now, the next step for you is to create AI agents that automate workflows using Amazon Bedrock and integrate with RAG. To deploy your application, you can use AWS services like ECS, Lambda, or other Bedrock-managed services.
In Part 3 of this series, we’ll explore how to scale RAG architectures in production, improve performance, and ensure seamless integrations.
Conclusion
RAG with AWS Bedrock makes models smarter by adding real-world context to its responses. That being said you’ll get more accurate answers, and reduce costs since you’re only pulling in the data you actually need. Anther thing is that AWS handles the backend, so you don’t have to stress about infrastructure.

Relevant Posts
.webp)

